
Today I was reading a whitepaper on VMware FT and came across some cool facts. In this post I am going to share some excerpts from that whitepaper.
Server virtualization has become very popular and grown very fast in last few years and enterprise started to use virtualization more and more to gain the benefits provided by virtualization such as:
1: Higher server consolidation ratios.
2: Better resource utilization (Using DRS).
3: Lower power consumption (Leveraging DPM).
4: Increased workload mobility via technologies such as vMotion and svMotion.
Features such as Distributed Resource Scheduler (DRS) and Distributed Power Management (DPM) are giving organizations a flexibility to go for a even higher consolidation ration than ever before. DRS is now a very trusted feature and almost all organizations are happy to use it in fully automated mode which was not the case earlier when DRS was introduced by VMware.
DRS and DPM complement the hardware evolution trends by applying dynamic resource allocation to lower the capital and operating costs in a datacenter.
However increased consolidation ration also brought some risks with it. As more business-critical workloads are deployed in virtual machines, a catastrophic failure of a single physical server might lead to an interruption of a large number of services.
VMware understood this and thus tried to address the availability issues for mission critical workloads by introducing features such as VMware HA, Site Recovery Manager (SRM) and VMware Data Protection (VDP) over the time.
These solution works very smartly by disassociating the virtual machine state including all business logic from the underlying hardware and applying data protection, disaster recovery, and high availability services to virtual machines in a hardware-independent fashion.
For virtual machines that can tolerate brief interruptions of service and data loss for in-progress transactions, existing solutions such as VMware HA supply adequate protection. However, for the most business-critical and mission-critical workloads even a brief interruption of service or loss of state is unacceptable.
So for the workloads that cant suffer service discontinuation even for a single second VMware introduced a feature called Fault Tolerance. Before diving into FT lets see how super high availability was achieved in older days when there was no virtualization.
Fault Tolerance in the Physical World
All fault tolerance solutions rely on redundancy. For example, many early fault tolerant systems were based on redundant hardware, hardware failure detection, and failing over from compromised to properly operating hardware components.
In older days high availability solutions was achieved via 2 ways:
a) Using fault tolerant servers based on proprietary hardware.
b) Using software clustering.
Fault Tolerant Servers
Fault tolerant servers generally rely on proprietary hardware. These servers provide CPU and component redundancy within a single enclosure, but they cannot protect against larger-scale outages such as campus wide power failures, campus wide connectivity issues, and loss of network or storage connectivity.
In addition, although failover is seamless, re-establishing fault tolerance after an incident might be a lengthy process potentially involving on-site vendor visits and purchasing custom replacement components. For physical systems, fault tolerant servers provide the highest SLAs at the highest cost.
Software Clustering
Software clustering generally requires a standby server with a configuration identical to that of the active server. The standby must have a second copy of all system and application software, potentially doubling licensing costs. A failure causes a short interruption of service that disrupts ongoing transactions while control is transferred to the standby. Application software must be made aware of clustering to limit the interruption of service. However, the potential for data loss or corruption during a crash is not fully eliminated.
An example of such a system is an application built around Microsoft Cluster Service (MSCS).
VMware Fault Tolerance
VMware FT address the above issues by leveraging encapsulation properties of virtualization by building high availability directly into the x86 hypervisor in order to deliver hardware style fault tolerance to virtual machines.
It requires neither custom hardware nor custom software. Guest operating systems and applications do not require modifications or reconfiguration. In fact, they remain unaware of the protection transparently delivered by the ESXi hypervisor at the x86 architecture level.
FT relies on VMware vLockstep technology. When FT is enabled on a VM, a secondary copy of the VM is spawned immediately. The secondary VM runs in virtual lockstep with the primary virtual machine. The secondary VM resides on a different host and executes exactly the same sequence of virtual (guest) instructions as the primary virtual machine. The secondary observes the same inputs as the primary and is ready to take over at any time without any data loss or interruption of service should the primary fail.
FT delivers continuous availability in the presence of even the most severe failures such as unexpected host shutdowns and loss of network or power in the entire rack of servers. It preserves ongoing transactions without any state loss by providing architectural guarantees for CPU, memory, and I/O activity. The two key technologies employed by FT are vLockstep and Transparent Failover.
vLockstep Technology
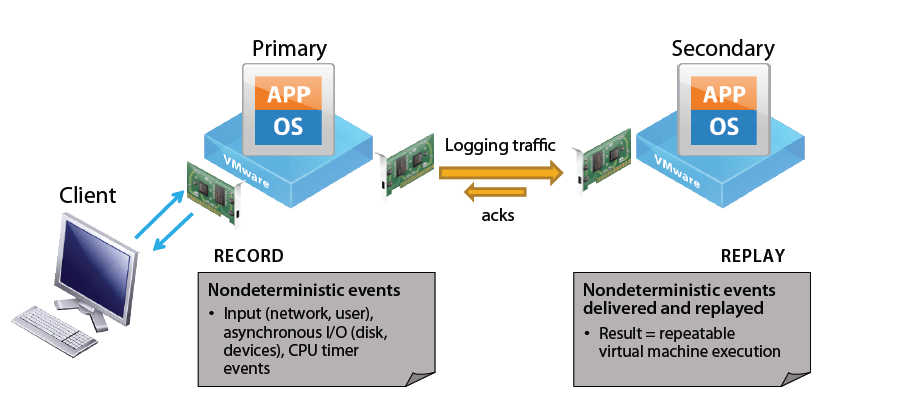
vLockstep technology ensures that primary and secondary VM’s are identical at any point in the execution of instructions running in the virtual machine. vLockstep accomplishes this by having the primary and the secondary execute identical sequences of x86 instructions. The primary captures all non-determinism from within the processor as well as from virtual I/O devices.
Examples of non-determinism include events received from virtual network interface cards, network packets destined for the primary virtual machine, user inputs, and timer events.
The captured non-determinism is sent across a logging network to the secondary. The secondary virtual machine uses the logs received over the logging network to replay the non-determinism in a manner identical to the actions of the primary. The secondary thus executes the same series of instructions as the primary.
Graphic Thanks to VMware
In my initial days as VMware Admin when I learned about VMware FT, always there was one question in my mind. If both primary and secondary VM have exactly the same configuration including networking stack, why don’t we get an IP address conflict on network. This I asked 2 times in my interview and never got the answer. Then when I was reading vSphere Design book, I came to know across the reason behind it. Same is explained as below.
Both the primary and secondary virtual machines execute the same instruction sequence and both initiate I/O operations. The difference between execution of instructions lies in the way how output is treated.
The output of the primary always takes effect: disk writes are committed to disk and network packets are transmitted, for example. All output of the secondary is suppressed by the hypervisor. The external world cannot detect the existence of the secondary and, at all times, treats a fault tolerant virtual machine as single unit executing the workload.
Transparent Failover
Because of the way vLockstep works, the existence of the primary and secondary VM is hidden from the outside world, which observes only a single virtual machine image executing a workload. VMware Fault Tolerance must be able to detect hardware failures rapidly when they occur on the physical machine running either the primary or the secondary VM and respond appropriately.
The hypervisors on the two physical machines where primary and secondary are running establishes a system of heartbeat signals and mutual monitoring when FT is enabled. From that point on, a failure of either physical machine is noticed by the other in a timely fashion. Should a failure happen on either physical machine, the other physical machine can take over and continue running the protected virtual machine seamlessly via transparent failover.
Transparent failover can be explained using following example:

Lets suppose the physical machine running the primary VM has failed., as shown in above figure. The hypervisor on the secondary physical machine immediately notices the failure. The secondary hypervisor then disengages vLockstep.
Hypervisor running on secondary physical machine has full information on pending I/O operations from the failed primary virtual machine, and it commits all pending I/O. The secondary VM then becomes the new primary. This is illustrated in step-2 of above figure.
This terminates all previous dependencies on the failed primary and after going live, the new primary starts accepting network input directly from physical NICs and starts committing disk writes. The VMkernel unblocks the suppressed instruction capabilities in secondary VM. There is zero state loss and no disruption of service, and the failover is automatic.
After the initial failover, a new secondary VM is spawned automatically by VMware HA. This is shown in step 3 of Figure. The new primary hypervisor establishes vLockstep with the new secondary, thus re-enabling redundancy. From this point onward, the virtual machine is protected once more against future failures.
The entire process is transparent (zero state loss and no disruption of service) and fully automated. FT deals similarly with the failure of the host executing the secondary virtual machine. The primary hypervisor notices the failure of the secondary and disengages vLockstep. The services provided by the primary virtual machine continue uninterrupted. A new secondary is created and again vLockstep is established between the primary and secondary VM.
Does FT supports failback?
So we have seen failover is transparent with FT and without any disruption of services. What about failback? What happens when primary server running the primary VM comes back online after recovering from failure. What happens now? Will the original primary (which got failed) becomes secondary or will it become primary again and force the new primary (which was secondary before the failure) to become secondary.
This was some questions which kept me waiting for a long time before I got a correct explanation. I discussed this with many of the colleagues of mine and each one have their own version of answer.
So answers for above question is “NO, FT doesn’t supports failback“. Even after the physical server which comes online after failure, it is not going to disrupt the current pair of primary-secondary FT VM. The original primary VM which gone down due to host failure never comes back online again. All the memory pointers of failed primary VM is deleted. There can’t be more than 2 VM’s at any given time in a FT pair.
Do VMware FT protects against OS failures?
This is also one question of great interest. We have seen how FT protects mission critical workloads against host failures. But what about OS failures? Does FT provides any protection against the failures which happens inside the guest os running in virtual machines.
Answer to this question is also a “NO“. FT can’t protect against the OS failures. Since primary and secondary VM’s are in vLockstep and maintains same consistent state, so a failure like BSOD in primary or a corrupt dll will also be replicated to secondary. So if a primary fault tolerant VM goes down due to BSOD, secondary will also suffers BSOD.
Till now there is no way FT protect against this. May be in future VMware make FT more intelligent to address this kind of failures as well.
As of now VMware has features like VM monitoring and App HA to address these kind of issues but it requires a bit of downtime and services are interrupted till the time failure has happened and recovered.
I hope you enjoyed reading this post. Feel free to share it on social media if this post is informational to you. Be Sociable 🙂
One thought on “Diving Deep into VMware Fault Tolerance”